Playing a game of GANstruction
It's all a game of construction — some with a brush, some with a shovel, some choose a pen.
Jackson Pollock
…and some, including myself, choose neural networks. I'm an artist, and I've also been building commercial software for a long while. But art and software used to be two parallel tracks in my life; save for the occasional foray into generative art with Processing and computational photography, all my art was analog… until I discovered GANs (Generative Adversarial Networks).


Since the invention of GANs in 2014, the machine learning community has produced a number of deep, technical pieces about the technique (such as this one). This is not one of those pieces. Instead, I want to share in broad strokes some reasons why GANs are excellent artistic tools and the methods I have developed for creating my GAN-augmented art.
But first, take a look at my art for some concrete examples of what I'll be discussing:
Powered by flickr embed.Portrait of a GAN as an artist/critic game
So what is a GAN and what makes it so attractive for an artist?
We can imagine the process of art-making as a kind of game. This game's action takes place in an art studio, and there are two players: a Critic and an Apprentice Artist. The goal of the Apprentice Artist is to generate pictures in the style of her master without copying the master's originals. The goal of the Critic is to decide whether the art he sees is by the apprentice or the master. Round after round, the apprentice and the critic compete with each other. As the apprentice becomes more skilled at imitating the style of her master, the critic is forced to become better at distinguishing the master's work from the apprentice's, and as the critic becomes better at this, so too must the apprentice become even better at imitating the style of her master.
A GAN is a neural network architecture that simulates this process; the role of the Critic is played by a discriminator network D, and the role of the Artist Apprentice is played by a generator network G. Through round after round of this "game," the generator network becomes better and better at imitating the style of the master — that is, the content of your input dataset.

And what is your role? Well, you tweak the game rules (network hyperparameters) and also become a curator. As a curator, you must make selections from the output of the GAN as it produces numerous images in different compositions, color, and texture combinations, with varying degrees of divergence from the images it was trained on. And curation is hard — sometimes you find yourself drowning in interesting images when you want to keep them all!

But working with GANs is above all exhilarating. With GANs, there is the adventure of new models and new datasets. There is an element of surprise, unlike with any other digital tool. There is a certain unpredictability that inspires, unblocks, and creates something special — something that goes far beyond Instagram filters or ordinary style transfer.
Why CycleGAN?
There are various types of deep learning techniques used for generative art.
The most popular ones are:
- GAN/DCGAN, the original method as described above:
4 years of GAN progress (source: https://www.eff.org/files/2018/02/20/malicious_ai_report_final.pdf … )
— Ian Goodfellow (@goodfellow_ian)
- Neural style transfer, which applies the style of one image to the content of another:

- Paired image translation techniques, like Pix2Pix, need a dataset with paired source and target images for training:
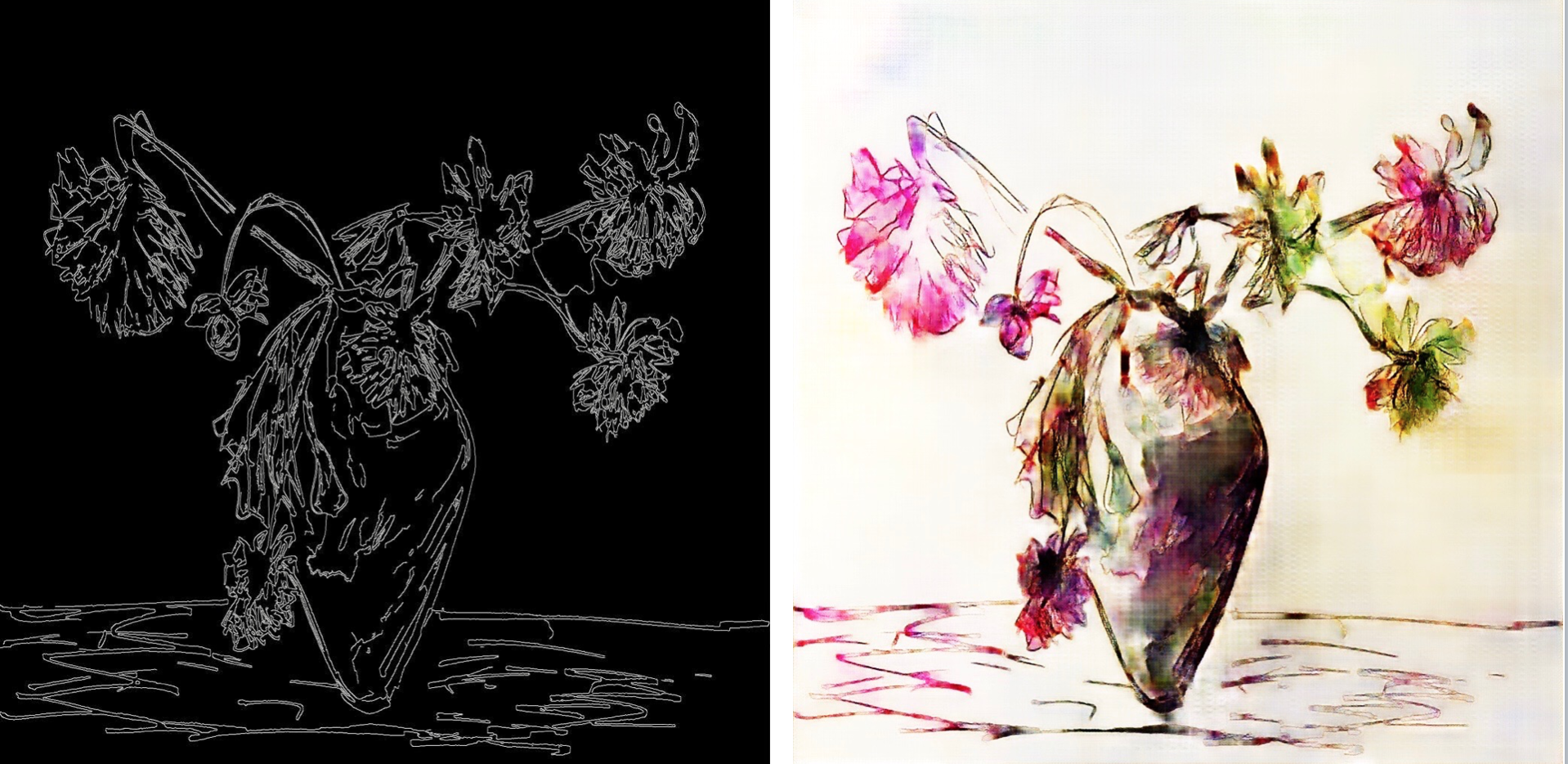
- Unpaired image translation techniques, like CycleGAN, do not:

Wonderful art has been created with all of these techniques. So why did I end up working almost exclusively with CycleGAN
? In a nutshell, CycleGAN lets you train a network to transform images with the form of one dataset (the input domain) to have the textures of another dataset (the target domain). This is important; per computer vision pioneer Alyosha Efros, we are "still in the texture regime."
I first used CycleGAN for a work project, but was so enamored by its power for texture imitation that I wanted to repurpose it for generative art. CycleGAN gives you the ability to work in high resolution with datasets of comparatively small size, and the model trains quickly — instant gratification!
My first project was to translate my food and drink photography into the style of my still life and flowers sketches. Each dataset consisted of 300 to 500 high resolution images. For the whole month I just ran various experiments, mostly around the input data crop size. I spent hours sieving through the output images, pulling out those that looked interesting.

My floral drawings were transformed into hallucinating snacks, and my drink photography became interesting — my visual world exploded. Finally, with certain trepidation, I shared them with my art mentor. Her reaction: "I don't know anything about software, but you're into something with those! Keep going!"
And so I kept going. As I became more familiar with the framework, I continued experimenting with other dataset combinations — floral sketches to flower pictures, landscape sketches to landscape photography, and more. Some experiments failed; others were quite successful.


Practical advice
Here are a few tricks I've learned from several months experimenting with CycleGAN:
- As the original CycleGAN paper observed, "translations on training data are often more appealing than those on test data." So in many cases, I use subsets of training data for inference — my goal is not generalization, my goal is to create appealing art.
- Often, I start the initial training of my model on larger datasets, then fine-tune it on smaller subsets for particular effect. Here's an example: these images were generated by a landscape model that was fine-tuned on Japanese poetry book covers.
- It's worth watching the dashboard as the model trains. The CycleGAN reference implementation allows you to set the display frequency, and I keep it pretty high, on the watch for interesting imagery. This process was like meditation for me — staring at visdom's UI and breathing in and out with the loss function.
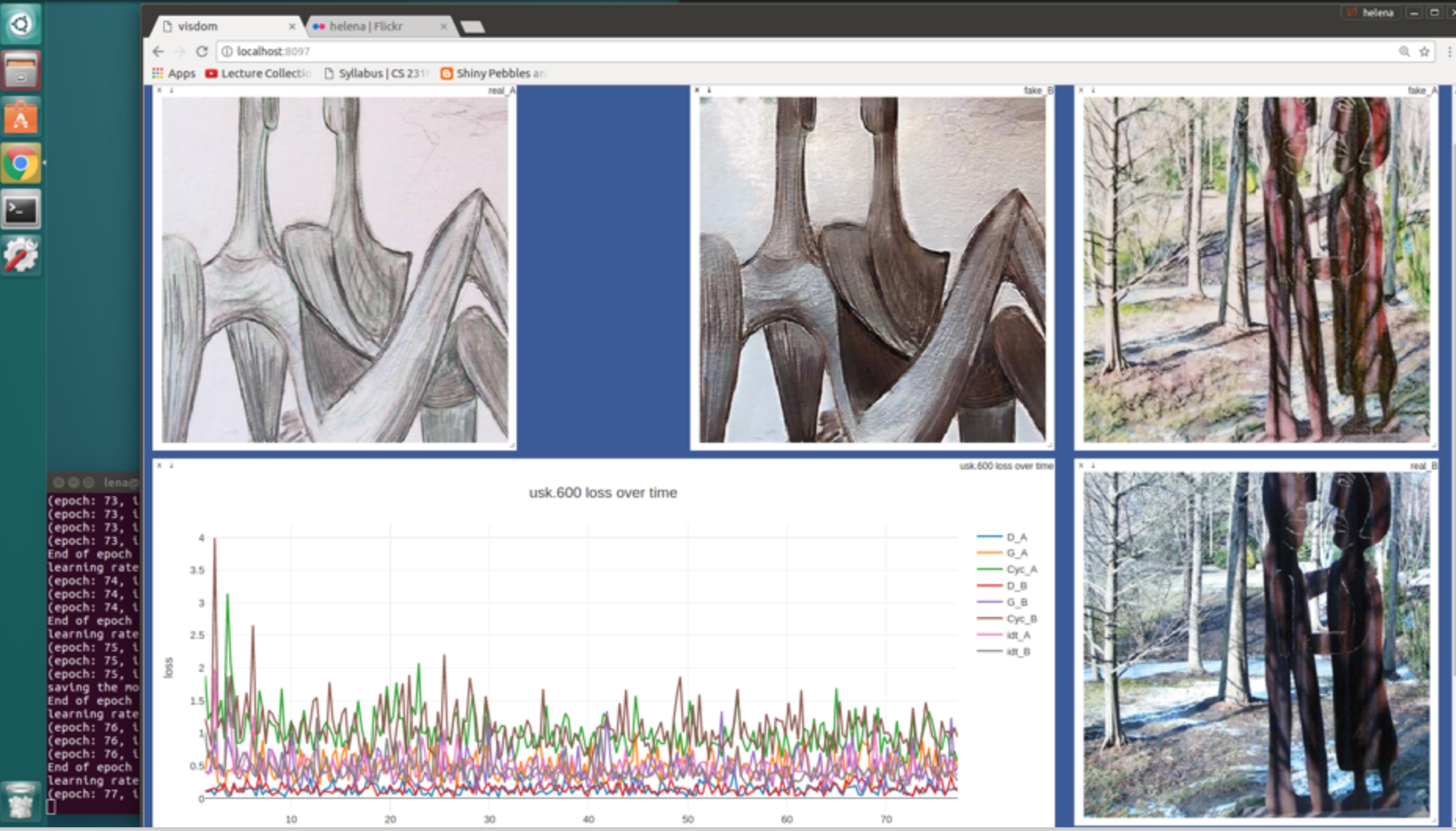
- As the training progresses and results became more and more intriguing, increase the checkpoint saving frequency.
- Save all the parameters of the experiments so you can recreate them later. (Though, to be honest, it's not a big deal if I can't reproduce some results — new experiments bring new excitement!)
- During inference, the images in the target set won't affect the appearance of generated images. That doesn't mean that you don't care what you put in that target set. Remember, you have two generators. Don't leave the second one idle — interesting artifacts might appear, like reconstructed images where the generators try to reconstruct the input images.
- By default, CycleGAN uses instance normalization and batch size of 1. But once you learn the rules you can start breaking them. What if you use batch normalization and a larger batch size?
- Another technique worth exploring is CycleGAN chaining: training one model and using the results to train another one.
The images below are an illustration of the last two items — I used a set of my florals and set of portrait sketches. The first model translated between these two in grayscale using batch normalization. The next model upscaled and colorized the results of the first model.

- Beware of excessive texture
, especially when training on patches. My initial experiment of food to still drawings turned most of the latter into porridge; so it's worth spending some time to curate the training datasets.
On the other hand, as my watercolor teacher used to say: let the medium do it. True that — my sketch simply provides the foundation, and then I let the network do its thing; I don't fight, I just constantly tweak my #brushGAN toolkit (which consists of saved trained models, input datasets, and more).
Which brings me to the next point — save as many models as your disk space permits. Use those for your personal style transfer — and the result will beat the standard "Starry Nights" renditions every time.
Consider this list your springboard for exploration into CycleGAN and other GANs. These tips are only rough guidelines, and in your journey I'm sure you will come up with your own techniques depending on your datasets, your artistic sensibilities, and your goals. The most important thing is to be mindful of the images generated by your GAN so you can adjust the training process.
Tools of the trade
So far, we've covered the general process: collect some data, and start playing with it. Let's now talk about the tools.
No matter what neural net you choose for generative art, the deep learning setup is more or less the same. For the last year or so, all my work has been done on a server I built myself. My original setup lived on AWS, and though it was cheaper in terms of compute, the storage was a major headache — I wasted a lot of time moving the data from volumes to/from S3 and forgetting to disconnect volumes. Now I run my own server, with a GTX1080 GPU, a 275GB SSD and two 1TB HDDs and although I'm still constantly running out of space, the additional control I have over storage has been worth it.
Then there are the hyperparameters, the most significant of which is no doubt the image size. CycleGAN settings allow you to specify the image crop,but the maximum possible resolution depends on your hardware. On my GTX1080, the maximum was 400x400 for training. With inference you can go much higher, but results often suffer. To keep things simple for the first experiments, you might just want to use the CycleGAN default settings, where the images are loaded and rescaled to 278X278 and randomly cropped to 256X256. I have models trained on 1024/800/400 — sometimes from scratch, sometimes starting with one size and then changing it as the training progresses.
It's (almost) all about the data
Don't forget the datasets! It's a known fact that to train any deep learning network, you need a lot of data. Many AI artists use web scraping for dataset acquisition. But — contrarian me — I decided to use my own datasets instead, by which I mean my personal photos and drawings/paintings. There are obvious advantages to this:
- It will give uniqueness and cohesion to your art, both in style and subject matter.
- You don't need to worry about copyright.
- You get high-resolution images without a lot of preprocessing.
- With a camera, you can easily create datasets for specific colors and compositions.
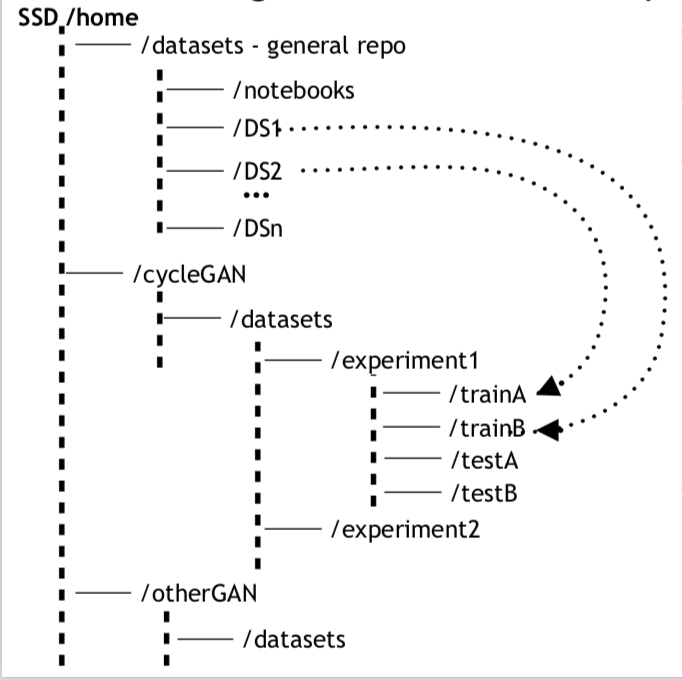
It's also worth saying a few words on the organization of my data repository. Here's the data structure and processing pipeline I have converged to using:
- General preprocessing: loading and adjusting photos from my smartphone
- Dataset composition: sorting photos based on subject matter/content/color/texture etc.
- A three-tiered storage organization:
- remote (cloud services like Flickr): for storing raw images. Flickr is good for set organization, and it offers a decent editor and unlimited storage.
- HDD: for long-term storage of unused datasets and weights
- SSD: for short- and medium-term storage of datasets and weights. My SSD is organized into several folders, including a general repository for raw images and a GAN-specific repository for preprocessed images.
- GAN-specific batch processing: I use Jupyter notebooks in a general /datasets repo, with utilities for square crops, canny edge detection (for Pix2Pix), sorting images, and so on.
Where to from here?
At this point, CycleGAN has become an essential part of my artist toolkit. Even as I started to experiment with new types of GANs, CycleGAN remained part of the generative pipeline: now I chain an output of the GAN to CycleGAN for deblurring, super-resolution and colorization in tandem with traditional CV techniques. Here are examples where CycleGAN was used to enhance the output of SNGAN from 128x128 to 512x512:


Now may be a good time to take a break, install CycleGAN and take it for a spin. I've been using the PyTorch implementation by the CycleGAN team (which also gets you Pix2Pix for the same price of admission), and it's a delight to work with due to its clean, well-documented, well-organized code and its excellent training dashboard.
For me, the best part of these experiments is that they make my visual world richer, make me observe and appreciate colors and texture more, make me think of new ideas and new projects, and make me want to draw and photograph more.
I'll conclude with the words of Alyosha Efros:
The visual world has long tails…
Follow Helena Sarin on Twitter.
No comments:
Post a Comment